Ruby, 我的书有点乱
学习Ruby,不是为了了解这个纯粹面向对象的东西到底是什么样子的,而是为了解决我面对的一些实际问题。比如说现在遇到的问题,自从买了Kindle后,我就隔三差五的会下载一些kindle电子书,有时候也会买一些,而我呢又是比较懒散的一个人,这样就搞的我的电子书有些乱,就那样胡乱的放着。这个时候你可能会说,花一点点时间整理一下不就好了嘛。嗯,那是因为你不是程序员。对于程序员而言,他们宁愿花很多时间写个程序来搞定。
在很多情况下,明明5分钟就能用手来搞定的事情,非得花几个小时写然后再花几天调最终还可能产生意料之外的错误的程序来做。这大致就是程序员碎了一地的节操吧。
我在网上下载以及从Amazon上买的电子书有以下几种情况让我心里有些许的不爽,可能是由于最近是处女座的日子,我也跟着有些强迫症起来。
- Life of Pi(少年pi的奇幻漂流) – Austin Lee.mobi
我不喜欢名字里面有括号括起来的东西,而且这部分内容完全是重复的,我向纯粹一些,把括号里面的内容给删掉。 - Of Mice and Men (Penguin Classics)_B00CS74W6Q.azw3
Amazon上卖的书,书的编号(比如_B00CS74W6Q)是直接放在文件名字里面的,好在我不是处女座,所以对这个东西是可以接受的,而且觉得它挺好,可以用来区分哪些书是下载的哪些书是买的。我正好打算把下载的书和买的书给分开,所以这个东西就派上用场了。 - 我下载的东西都是放在默认的Download目录里面,我想把他们都整理到Documents这个目录里面。
所以我就写了个Ruby脚本来做这件事。其实,目前为止仍然困惑我的一件事情是,Ruby除了做脚本还能做什么呢?
这个Ruby脚本很短小,所以就直接贴在这里了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
Ruby很有特色的一个地方就包括它的字符串处理,它不用像C语言一样来考虑内存管理,程序员也不必要担心字符串占用的内存空间[1].
比如可以直接这样给一个字符串赋值:
1 2 | |
此时str2是”we are a whole we are a whole”
妈妈说,再也不用担心用strcpy还是strncpy了…
另外一个有特色的地方是Ruby对于中文字符的支持,我们知道在UTF-8编码下一个汉字是占用3个字节,这可以很容易的用C语言来验证:printf(“%d\n”, strlen(“你好”)) 显示的结果是6。但是,在Ruby里面,printf(“%d\n”, “再见”.length)的结果是2,即它显示的是字数而不是字节数,这也是Ruby对中文支持很好的地方,或许是因为松本行泓先生是日本人的缘故吧。所以对于str = “你好”而言,在Ruby里面str[0]是”你”;而在C语言里面,str[0]则只是”你”的第一个字节。
看起来确实是挺酷的吧…
在执行完这个程序后,这些书就按照我的预期整理好了。但是,等等,让我们打开其中的书试试看。当我打开从网上下载的书时,一点问题都没有,然而当我打开从Amazon上买的书时,结果:
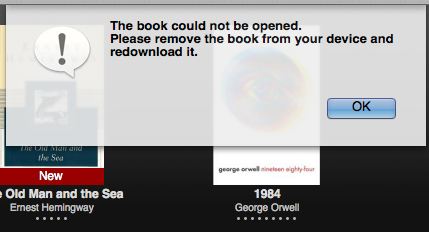
……
哈哈哈哈哈哈…
所以说,备份很重要~
P.S.
[1] guides.ruby
[2] 进来事情有些多,所以直到这个月最后一号才写这篇文章,写的也有些赶。