编译器输出函数的算法对性能的影响
TL;DR
对于这个问题的研究也是缘于我们firewall的UDP吞吐量的波动。
在之前讨论过通过Makefile,链接脚本和gcc的attribute属性来控制编译器输出函数的顺序。然而在做了这些工作后,依然存在无关代码commit后引起性能波动的诡异现象,在对比了不同版本的二进制文件后发现有些commit会引起函数顺序的重排,这些重排就容易造成性能的波动。于是我就开始了做这个方面的研究,来分析编译器是如何调整函数顺序的以及能否进行优化。
什么是call-graph
首先,要明白一个概念:call-graph。
call graph是用来表示函数调用关系的一个有向图。
我们可以通过gprof来获取一个函数的call graph,gprof是在函数运行过程中来获取函数调用关系(所以不会被执行到的函数就不会出现在call graph中)。
如下是一个简单的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
那么对应的call graph就是
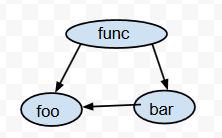
在call-graph里,函数称为节点(node),比如func/foo/bar就是节点;一个调用称为边(edge),比如func指向foo的那个边。这跟图论是一致的。
top level function
还需要明白一个概念:top level function。
接着前面的示例代码片段,我们加上main函数组成一个完整的程序。
1 2 3 4 5 6 7 8 9 | |
此时func()这个函数就是一个top level函数,即没有函数直接来调用的函数。
对于这一类的函数,由于没有函数来直接调用它,因而在函数的入口处就没有必要保存寄存器信息。 我们可以使用__toplevel这个属性来显示的告诉编译器这是一个top level function。
1
| |
编译器输出函数的顺序是怎么样的
我们来看下gcc的源码
1 2 3 4 5 | |
一些解释:
1. asmstatements function
这是Basic Asm (Assembler Instructions Without Operands),比如:
#define DebugBreak() asm("int $3")
Varpool variables
这个是所有的静态变量expand_all_functions是输出函数的主体,这个是我们接下来要关注的。
1 2 3 4 5 6 7 8 9 10 11 | |
也就是以revserse preodering方式来深度优先遍历call-graph,然后以这个顺序的逆序输出,即以bottom-up的方式来输出call-graph里面的node。
编译器以这个顺序来输出函数的目的是什么
编译器没有按照函数在文件里面的先后顺序输出,而是基于call graph输出。这样做是因为,子程序和他们的调用者在时间上可能相互接近,因此应当在放置时使得他们在空间上互不冲突,所以将子程序放在他们的调用者附近以减少页交换,并且使得频繁使用的和有关联的子程序在icache中以相互之间冲突较小的方式放置。
还要注意,它是以bottom-up的顺序输出,而不是按照top-down的顺序输出,这也说明,这样做优化的目的没有考虑函数的先后顺序,为什么不按照函数的调用顺序来输出呢?比如a调用b,那么就把b放在a的后面,这样在执行a的时候就把b给预取到内存不是很好么。事实上,预取是以cache line为单位的,一个cache line的大小是128字节或者64字节或者32字节,而函数的大小远不止这么大,函数调用时会有地址跳转,因而按照调用顺序来放置意义不是太大。
以bottom-up的方式来遍历call-graph也是基于一次遍历的考虑,这样可以在遍历call-graph的每一个节点时就可以采用合理的策略来分配寄存器。比如,在main函数里面使用的寄存器,只有在保存后才可以被它的子程序使用;相反,所有leaf functoin可以使用相同的寄存器,因为这些leaf function不会同时执行(单线程情况)。以bottom-up方式输出,那么在函数调用时,callee使用的寄存器是已知的因为callee已经被处理过了,通过避免重复使用这些寄存器就可以避免save/restore。
科普一些基本知识。
在有函数调用时,编译器将寄存器分为三类:
– callee-saved registers.
这些寄存器要求在函数调用时,由被调用者来保存
– caller-saved registers.
这些寄存器要求在函数调用时,由调用者来保存
– 4个参数传递寄存器
在函数调用时用来传递参数
比如对于MIPS而言,s0~s7是callee-saved, t0~t9是caller-saved,a0~a3是传递参数的寄存器.
这种输出顺序是否可以控制
通过源码我们可以发现在compile()这个函数里,有个flag可以决定是以自然顺序输出函数还是以优化顺序输出函数。
1 2 3 4 5 6 7 8 9 | |
这个flag就是通过-fno-toplevel-reorder 来控制的。这个选项是在gcc-4.1加入的,这个选项加入的目的是为了支持以前存在的依赖特定顺序的代码(参见gcc-4.1的release note)。
使用-fno-toplevel-reorder的坏处
使用这个选项后,gcc将按照函数在文件中出现的顺序输出,这可能会降低程序的性能,但是如果我们使用了attribute 来将热点函数给放到了一起,那么gcc的reorder对性能的影响就不是太大了,甚至gcc的reorder可能会降低程序的性能(这也说明gcc在这方面的优化做的还有待改进)。
使用这个选项后一个比较明显的坏处是,那些未被使用的static变量将仍然存在于最终生成的程序中,而如果不使用这个选项这些冗余的static变量会自动的被编译器给删除。
那些在程序中没有调用的函数,在call-graph中称为不可达的节点,他们跟这个选项无关,不论这个选项使用与否都会被删除。
1 2 3 4 5 6 7 8 | |
未完待续
对于编译器分配寄存器这一块,我的研究还不够深入,有些地方也不能很清楚的解释细节,这有些惭愧。