Lock-free、网络吞吐量性能、并发及其他
前段时间尝试更改我们系统里的并发实现,用lockfree来实现了一遍以提升网络吞吐量。在这个过程中遇到了一些很有趣的技术细节,在这里记录一下。
公司业务不便多说,我就借助dpdk的packet processing模型来说明一下。下图摘自dpdk.org。
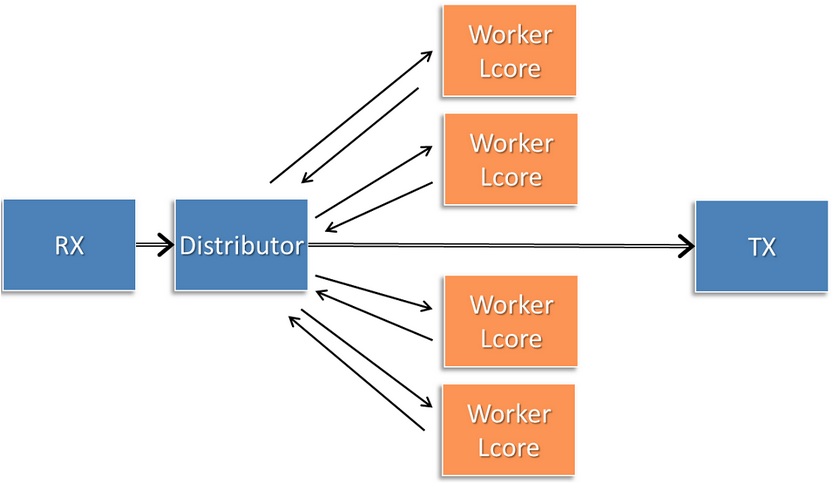
如上图所示,是一个典型的packet processing模型,RX这个线程接受到数据包后送给distributor,然后Worker Lcore这些线程从Distributor那里获取数据包来处理。和本次讨论无关的技术不在此阐述,我将其简化为更加清晰明了的下图。
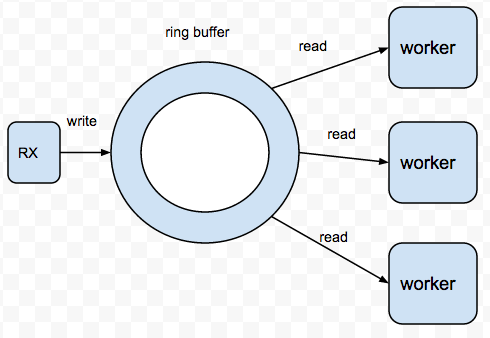
我们的问题简化为如下:已知ring buffer是一个大小为2048 * sizeof(long)的数组, 有一个RX线程往ring buffer里面保存mbuf的地址,有N个worker线程来从ring buffer里面获取mbuf的地址。在这种场景下如何来实现一个lock-free的buffer?
在Linux Journal上有一个现成的实现,不过很可惜,虽然他的方案很巧妙,但是存在一个bug,稍后会解释这个bug。
下面是一个简短实现这个lock-free ring的一段代码,我借鉴了linux journal上的那篇文章。具体的实现细节以及原理我不再描述,那篇文章描述的很详细,浅显明了。我在这里只解析它里面的那个bug。
1 2 3 4 5 6 7 8 9 10 | |
上面这两段代码均应该在那两个语句之间添加barrier,即:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
否则它就可能会被编译器(gcc)给优化为比如如下:
1 2 3 | |
之所以做这个优化,是因为计算机的空间相近性原则,编译器会尽量将临近内存操作给放在一起以提高cache的命中率。 对于共享内存模型的这种并发,C语言的编译器并不去关心哪些变量是共享的,它只是依据局部最优性原则来做优化。所以对于C程序员而言,在实现基于共享内存模型的这种并发时,C编译器的这种优化是很大的一个挑战, 它可能会引入一些很难以定位的bug。所以,用C来实现并发,尤其是lockfree的并发,是一个非常需要经验的技术活。
好在instruction reordering 这种bug是可见的,我们可以通过反汇编来发现这种bug。如下是有无barrier的一段反汇编代码对比(注:以下反汇编直接引自我在我们系统里的实现,跟上面代码有出入,但这不重要):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
instruction reordering引入的bug虽然挺折磨人,但毕竟是可见的。在并行程序里面还有一类bug则是完全不可见的,那就是memory reordering问题,这一类问题不仅仅是技术活了,更是意识活。在X86上,一般不会有memory reordering问题,因为它是strong order的,cache一致性做的比较好。但是在MIPS/ARM这种weak order的CPU上,memory reordering问题就比较突出,他们的cache一致性做的比较差,所以就需要显示的使用sync指令来保证cache的一致性,即通过软件来弥补硬件的不足。
同样是上面这个例子:
1 2 3 4 5 | |
虽然加了barrier,确保了语句A一定会在语句B之前得到执行,但是如果ptr_array_[]和thr_pos().head不在同一个cache line里面,就有可能存在thr_pos().head先被同步到内存,ptr_array_[]后被同步到内存的情况,那么在这个时间空窗内,thr_pos().head已经被更新,它的previous value就可以被其他CPU使用,就会导致该CPU还没有写入其他CPU就从ptr_array_[thr_pos().head & Q_MASK] 里读数据的情况,这自然会导致错误。如下图所示:
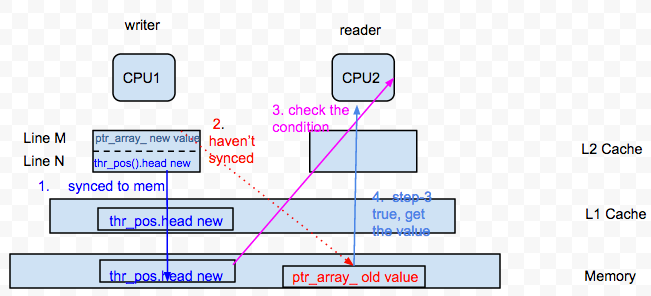
PS: 这个图的L1 cache和L2 cache画反了,哇咔咔
另外,在共享内存模型中关于lockfree算法的必备基本功是对atomic的认识。atomic是针对内存操作而言的,我们可以这样认为,如果一个语句对于同一个内存只访问一次,我们就认为它是atomic的。如果需要访问多次该内存,我们就得借助编译器或者操作系统提供的atomic函数来访问。
以下是一些简单的例子来说明一下:
1 2 3 4 | |
对于32-bit CPU而言,它无法用一条语句来操作32bit的立即数,因为机器码只有32bit。所以它会做如下拆分(MIPS):
1 2 3 | |
虽然这条语句被编译为了3条指令,但是它只有一次内存访问,所以这个语句是原子的。即,内存写操作是原子的。同样,内存读操作也是原子的。
1 2 3 4 | |
虽然这里会访问两次内存操作,读x时要访问x所在的内存,写y时要访问y所在内存。但是它只访问一次y,所以对于y内存而言,是原子的。
1 2 | |
12(sp)和16(sp)是不同的内存地址,所以这条语句对于y而言是原子的。PS:如果还需要保证写入y之前x不被改写,那就要借助atomic_write函数了。
1 2 3 | |
对于这条语句而言,首先它会从内存中取出x,然后做加法运算,最后将运算结果写入到内存。如下汇编:
1 2 3 | |
那么这条x++这条语句就不是原子的,所以就得使用atomic_add()来操作x。
简单的说,对于所有需要算数运算的操作,它都不是原子的。PS:只指对内存变量做算数运算
Ref.
- 我自己写的一个Single-Writer Multi-Reader lockfree的代码
Single-Writer Multi-Reader lockfree Ring