我给Linux Kernel的background Writeback贡献的一个patch
这是我帮同事分析热迁移镜像下载IO限速时看内核代码发现的一个问题。
然后给Linux Kernel提交了一个patch:mm/page-writeback.c: print a warning if the vm dirtiness settings are illogical.
该patch基于kernel 4.14-rc2,会在kernel 4.15.0上面发布。
问题背景
IO限速我们一般都是选择cgoup的blkio子系统,blkio子系统可以限制direct IO,理论上也可以限制sync IO,但是对async IO就无能为力了,所以才有了cgroup2的blkcg+memcg联合起来控制异步IO。
镜像下载是一个sync IO操作,所以理论上是可以通过blkio来进行限速的,但是事实上却没有限制住。于是我就去分析为什么这个sync IO没有限制住。
实验
我们做的限速如下, 读写最大都为30M bps。
1 2 3 4 5 6 | |
然后使用dd做如下测试:
1
| |
然后可以通过iostat来观察写的效果,可以发现,写入的速度不止30M,可以很快的达到磁盘的最大带宽。
即cgroup blkio失效了。
为什么blkio throttle在限制sync IO时失效了 ?
dd的做法是一次会写入bs大小的数据到内存,然后再根据相应的flag执行后续操作,如此依次进行count次。
这个行为可以通过strace来跟踪。
比如我们上面的那个命令,首先会写2000M的数据到内存,然后再根据oflag来执行sync写入到磁盘的操作。于是这就引入了问题,在往内存写的过程中可能会触发bdi writeback(包括background writeback和periodic writeback),于是blkio失控。
因而,blkio真正能够有效控制的只有direct IO。 如果想要控制sync IO,那么必须要关闭bdi writeback才可以。
backgroup writeback
如果写入的可回收的脏页数大于了后台回收的阈值,就会去唤醒后台回收。代码如下:
1 2 3 4 5 6 7 | |
这段代码在进程每次写文件时都会去执行检查。
“gdtc->bg_thresh” 即我们设置的vm.dirty_background_ratio的大小(在某些情况下可能不同)。
background writeback被唤醒的这个行为可以通过ftrace来观察,
1
| |
来使能对该事件的追踪。
backgroud writeback被唤醒后,就会去执行wb_workfn()这个handler。
同样这个行为也可以借助ftrace来跟踪:
1 2 3 | |
ftrace是用来分析内核逻辑的一个很强大很方便的工具: )
background writeback会将脏页比例给刷到dirty_background_ratio以下:
1 2 3 4 5 6 | |
vm.dirty_background_ratio
我们可以通过sysctl调整这个值的大小来设置系统中的脏页达到了多少后来唤醒刷盘。这个值的有效设置范围是[0, 100]。如果我们想在写数据时避免后台刷盘,那就需要把该值调大一些。
同事就调整该值来做下对比验证,在做测试的几组数据中,我发现,他有时候会把vm.dirty_background_ratio设置的很大,然后vm.dirty_ratio设置的很小。
我就很好奇, dirty background ratio还可以高于dirty ratio的啊,高于他之后会发生什么哪?因为我一直以来都是以为dirty ratio的值应该要大于dirty background ratio。
很困惑,于是就去内核代码一看究竟。
问题分析
虽然我们可以成功的将vm.dirty_background_ratio设置的大于vm.dirty_ratio,但是在实际运行中会检查出这种情况然后做出相应调整:
1 2 3 | |
如上所示,如果vm.dirty_background_ratio大于vm.dirty_ratio,那么真正的backgroun阈值会被调整成为vm.dirty_ratio的1/2.
于是这就会带来一些困惑,我们明明设置成功了,但是实际起作用的值却跟我们设置的不一样!
所以为何不在设置之初就做检查哪?只让你去设置合理的值。
所以我就给内核提交了一个patch,对dirty/backgrou ratio, dirty/background bytes做合理性检查,并且ratio的有效范围指定为(0, 100),因为这四个值任一个为0%或100%都是很危险的,可能会产生一些不可预料的行为。
提交内核patch
如何向内核提交patch ?
具体步骤可以参考FirstKernelPatch,
也有篇比较简洁的中文blog:如何向 Linux Kernel 提交 Patch
不再赘述
Linux Kernel开源管理方式
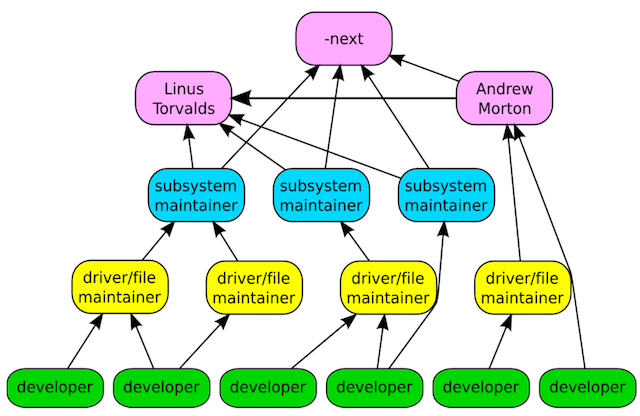
图片来自Greg在LC3 Beijing上的演讲Linux Kernel Development – How It All Works.
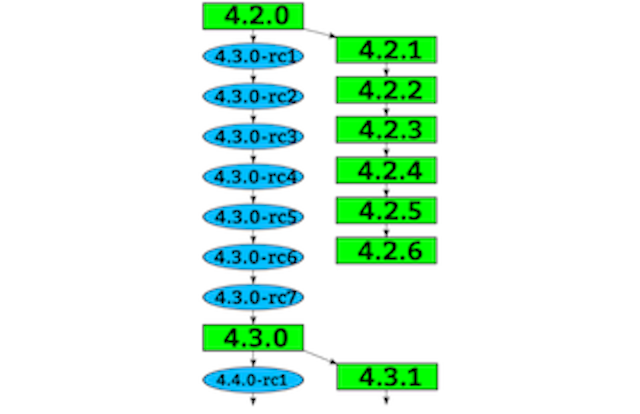
Linus毫无疑问是Linux Kernel的一号人物,Andrew Morton是二号人物,涉及memory management的一些改动一般都会有Andrew Morton先合入linux-mm tree,再合入linux-next tree. 如果当前stable版本是4.13,那么mainline就是4.14.0-rcX, linux-next对应的版本版本就是4.15.0。在Linus发布4.15.0-rc1的时候会将linux-next tree以及其他的一些feature-next tree给merge到mainline。
也有一些会直接由Linus合入到mailine或者stable,其他的一些maintainer有时候也会和乳mainline或stable。
然后rc版本周期的变化(一般一周一次), 共约七八个rc版就会发布4.14.0,然后再发布4.15.0-rc1。
Andrew Morton可以称为Linux Kernel的执法官,很多大家争执不定的问题都由他来一锤定音,在我提交的这个patch过程中他就扮演了这个角色。
我的patch提交过程
在周六分析了一天后,我就给Linux Kernel提交了patch: mm: introduce sanity check on dirty ratio sysctl value
这些maintainer们周末一般都休息的,所以page-writeback.c这个文件的maintainer Jan Kara (at Suse Labs)到了周一他上班后才回复我邮件然后提了一些建议。
最终[v4] mm: introduce validity check on vm dirtiness settings 获得了他reivew通过:
1 2 3 | |
然后我就给Andrew Morton发送了这个patch,同时cc linux-mm mailing list,一个大约100行的patch。
maintainer的争执
结果另外一个maintainer Michal Hocko(at Suse Labs)跳出来说:
In general we do not try to be clever for these knobs because we _expect_ admins to do sane things.
他的意见是只需要完善Document即可,不需要修改内核代码。因为dirty ratio/bytes比dirty background ratio/bytes 设置的大是个常识,有经验的系统管理员都会这样做的。
然后Jan Kara怼了回去:
So I personally think that the checks Yafang added are worth the extra code. The situation with ratio/bytes interface and hard/background limit is complex enough that it makes sense to have basic sanity checks to me.
俩人一个实验室的,就不能先当面讨论下再反馈意见给我么:)
Andrew Morton出马
大概Anrew Morton看到了他们的争论,就站出来问了我一个问题,这个问题体现出来Andrew是个非常细心并且考虑很全面的一个人。
他说,做了你的这些检查后,如果我们会同时调整dirty_background_bytes和dirty_bytes, 如果想要调大系统中的脏页数量,那就得先设置dirty_bytes然后再设置dirty_background_bytes;如果要调小呢,那就得先设置dirty_background_bytes,再设置dirty_bytes。 但是我们现有的一些设置脚本可能顺序是反过来的,当然这些脚本是不对的。你的这些检查会让这些脚本不work了对不对 ?
然后我回复Andrew说,如果顺序不对的话,第一个设置会失败。然后会有打印日志来提醒系统管理员设置的有问题,以便做改正。这种情况下要比第一个设置成功要好一些。
因为第一个设置成功的话,实际起作用的值跟设置的值会不一样,这样子可能会引发一些跟系统管理员期望值不一样的现象。
比如说,调高系统中的脏页数,首先把dirty_background_bytes给调大不想早早的唤醒后台刷盘,如果这个值高于了当前的dirty_ratio对应的值,那么后台刷盘阈值实际就为dirty_ratio的1/2,也就是反而变小了,这个时候就可能会唤醒后台刷盘。
然后Andrew答复我,大意是,宁愿出点错误也比不work强,还是只是加个打印告警吧!
我就按照Andrew的意见修改后提交了给他。
最后Andrew发了一个确认邮件给我:
一番感慨
从这里也可以看出来,内核里面的很多缺点都是向历史包袱妥协的结果,得在历史包袱和完美做法之间取一个折衷,即一个合理的做法。