Docker背后的技术: Namespaces
背景知识:一句话概括Docker
Docker是基于Linux container的一个容器管理工具。它的作用是将应用程序给容器化,以保证在同一个Kernel上运行的应用程序的运行环境相互隔离,让容器内的这些进程觉得在这个系统里只有这些进程而感知不到其他进程的存在。与Docker容易进行比较的一种技术是KVM,KVM的作用是虚拟化,它实现一些硬件的虚拟化,这样来在一个VM里运行其他的Kernel。Docker的优点是可以快速的创建线程,并且以native的速度快速执行,高效的使用系统资源。
Docker的概貌如下图
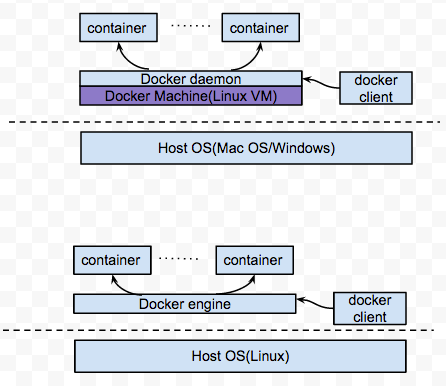
Docker的原生内核是Linux,如果要在非Linux(Windows/Mac OS)上运行Docker还是得需要有VM。
Docker用到的内核技术
在Linux Kernel里对资源进行控制的机制是cgroup,实现资源隔离的机制是namespaces, cgroup和namespaces就是Linux container用到的两个内核机制。
Namespaces背景知识:进程地址空间
下图是32-bit Linux典型的地址空间分布:
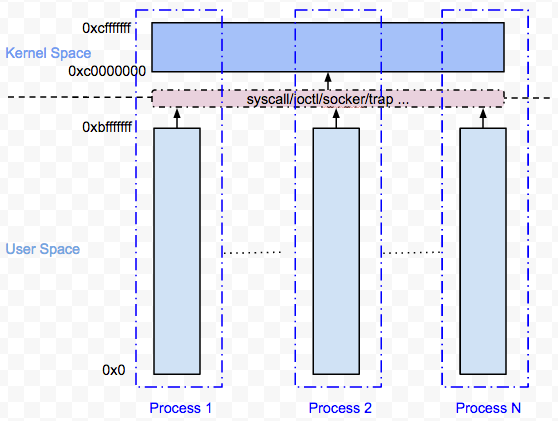
如图所示,在User Space(0~3G)各个进程拥有自己独立的地址空间,它们互相看不到对方。这些进程通过Kernel API(syscall/ioctl/socket/trap…)进入Kenrel Space(3G~4G),然后使用内核提供的服务,所有的进程共享同一个Kenrel Space。
这样带来的结果就是,虽然在User Space所有的进程都有独立的地址空间,互相看不到对方,然而在Kernel Space,他们是感知到其他进程存在的。
如何让进程在使用内核服务时感知不到其他无关进程的存在,就产生了namespaces这个技术。
Namespaces:抽象,封装,多实例
在内核里面有很多全局变量,比如init进程(1号进程),比如根目录(/),比如时钟,比如路由表,这些全局变量就是内核提供的一些全局资源。实现进程的隔离,首先要解决的就是这些全局资源问题,让各个容器内的进程都有自己独立的全局资源,即全局资源的多实例化,每个容器内都有这些全局资源的一个实例。具体到编程角度,就是将这些全局变量给封装。 比如对于根目录(/)的如下封装: (摘自Kernel-3.9)
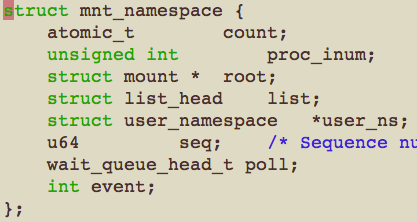
mnt_namespace是mount namespaces的抽象数据结构。mount namespaces是内核里已经实现的namespaces中的一个,它的作用是隔离挂载点(mount point), 这样一个mount namespaces里的这组进程只能看到自己的目录结构,并且把它的挂载点当作根目录,从而看不到它的挂载点之外的目录结构。这有些类似于chroot(2)这个系统调用,mount namespaces比chroot好的地方在于,chroot只是将子目录设置为应用程序的根目录(/), 在chroot的根目录下不会有系统根目录下的其他子目录,而mount namespaces则会这些子目录的一个实例。
来看下docker的具体示例。
下图是在Host OS(我的Macbook的OS)里的目录结构:
然后我们在docker machine里启动一个ubuntu container,看下这个container的目录结构:
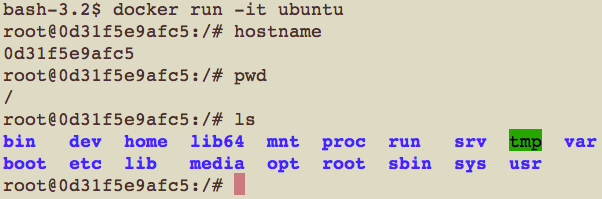
可以看到这是一个新的目录结构。其中hostname那一项是该container的ID。 为了实现mount namespaces,mount()以及umount()这两个系统调用都要做出相应的改变。他们不再操作对所有进程均可见的全局挂载点,取而代之的是只影响跟该mount space相关的进程。
Namespaces的过去,现状及未来
Mount namespaces是Linux Kernel里最先出现的一个namespace,它是为了解决clone()系统调用而增加的,由于当时想不到还会有其他的namespace,所以就给mount namespaces起了一个比较通用的名字,叫做CLONE_NEWNS,即new namespace的意思。那个时候更不要说会预见到有container这种东西了。 伴随着container这个概念的产生,增加了更多的namespaces来满足需要。
- Network namespaces: 用来实现网络资源(网络设备,IP地址,IP路由表,端口号,等等)的隔离。
- PID namespaces: 用来实现PID号这个资源的隔离,这样在不同的PID namespaces中可以使用同一个PID,比如每个namespace都有它自己的init进程(PID 1),init进程是所有其他进程的祖先进程。
- IPC namespaces: 用来隔离System V IPC标识以及Posix消息队列, 这样就使得不同Namespace之间的进程不能直接通信,就像是在不同的系统里一样
- UTS namespaces: 用来封装uname()这个系统调用。可以虚拟出一个有独立主机名.
- User namespaces: 用来隔离用户ID和组ID。那么这样就可以让一个用户在某个container里拥有root权限但是在整个系统里却没有root权限。
我前面提到的这6个namespaces就是目前最新Linux Kernel(Kernel-4.2)里所有已实现的namespaces。由于Linux Kernel里拥有非常多的全局资源,随着越来越多应用场景的出现,每一个全局变量都有可能被封装进namespace,这就不可避免在将来会产生新的namespace,比如甚至系统时间都可能会被封装进namespace这样不同的container就会有不同的时间。由此伴随而来的一个问题就是,如何来组织这些namespaces来避免namespace种类的大爆炸以及系统复杂性的增加,这会是一个挑战。
Linux的Namespaces,FreeBSD的Jails
在FreeBSD上面,与Namespaces类似的机制叫做Jails。Jals具有如下一些功能:
- 目录树
实现效果和Linux的Mount namespaces类似。 - 主机名
每个jail可以有自己的主机名。这类似于Linux的UTS namespaces。 - IP地址
分配给jail的IP地址,一个jail的IP地址通常是系统里存在的网络接口的IP地址。这类似于Linux的Network namespaces。 - 命令
jail内部的执行路径PATH,这个路径是相对于该jail环境的根目录的。
jail有自己独立的用户组和root用户,并且这些用户都限制在这个jail的内部。这类似于Linux的User namespaces。
所以FreeBSD的Jails和Linux的Namespaces具有类似的功能,都是为了系统虚拟化。因而Docker移植到FreeBSD上面也是有可能的。