为什么使能RPS/RFS, 或者RSS/网卡多队列后,QPS反而下降?
TL;DR
RPS
即receive side steering,利用网卡的多队列特性,将每个核分别跟网卡的一个首发队列绑定,以达到网卡硬中断和软中断均衡的负载在各个CPU上。
他要求网卡必须要支持多队列特性。RPS
receive packet steering
他把收到的packet依据一定的hash规则给hash到不同的CPU上去,以达到各个CPU负载均衡的目的。
他只是把软中断做负载均衡,不去改变硬中断。因而对网卡没有任何要求。RFS
receive flow steering
RFS需要依赖于RPS,他跟RPS不同的是不再简单的依据packet来做hash,而是根据flow的特性,即application在哪个核上来运行去做hash,从而使得有更好的数据局部性。
我们可以看到很多案例,使用这些特性后提醒了网络包的处理能力,从而提升QPS,降低RT。
但是,我们知道,任何一个优化特性都不是普遍适用的,都有他特定的场景来应用。
很多人对此可能会有疑惑,那很多优化功能不是都已经作为默认配置了么,如果不是普遍适用的,干嘛还要作为默认配置呢?
其实很简单,一个优化特性可以作为默认配置,依据我的理解,只需要满足下面这些特征即可:
- 对某些场景可以显著提升性能
- 对大部分场景无害
- 对某一部分场景可能会损伤性能
所以Linux的很多配置都是可以灵活配置供选择的。
下面我们就来看下RPS这些特性在哪些场景下才能发挥作用。
问题描述
业务方在使用KVM虚拟机进行性能压测时,发现某一个核的softirq占比特别高,如下所示:
1 2 3 4 5 6 7 | |
一句话解释:这个kvm虚拟机只有一个网卡,有网络包到达这个网卡后,它会给某一个cpu(如果没有设置亲和性,这个可以认为是随机的一个cpu,然后就会一直固定在这个cpu上)发中断,通知该cpu来处理这个包,然后cpu就会触发一个软中断把该包送到tcp/ip协议栈(对于tcp包而言)里去处理,该包被放入某一个socket的receive buffer中(如果是一个数据包),软中断结束。
%soft就是指的CPU耗在软中断处理上的时间。
可以看到核1的%soft很高,其他的核的%soft基本为0.
所以就想着把核1的%soft给均摊下,是否可以提升QPS。
我们想到的方法是网卡多队列,或者RPS/RFS。用这种手段来把网卡软中断给均摊到其他的核上去。
其实,看到前面mpstat的显示,如果对网卡多队列,RPS/RFS很熟悉,就会意识到他们在这里不适用。
可惜理解的不深,交了这次学费。
使能网卡多队列后,果然是QPS不但没有提升,反而有下降。
下面就是这次调优交的学费。
为了使描述更清晰(其实是因为我做分析的这个kvm虚拟机上没有网卡多队列,但是不影响,导致性能下降的原因是一致的),我们只分析RPS来看下为什么性能会下降。
RPS的原理概述
- 基于CentOS-7
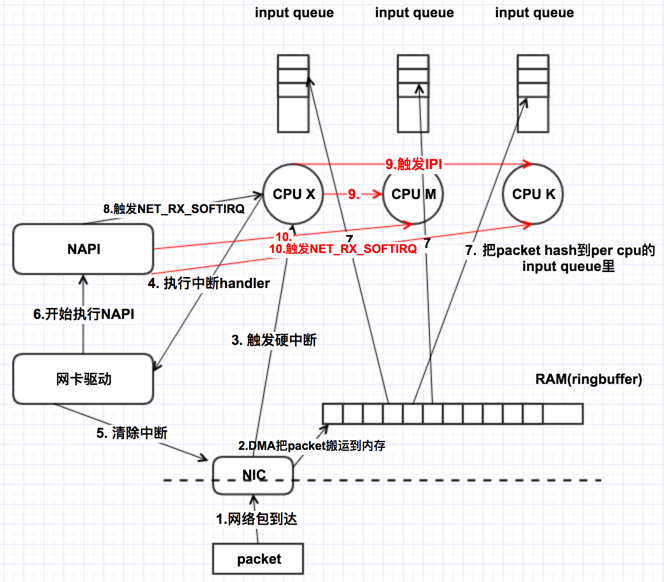
在这之前,软中断只能在硬中断所在CPU上处理,使用RPS后,网卡软中断就可以分发到其他的CPU上去做处理了。
使能RPS后为什么会导致QPS下降?
如上图所示,使能了RPS后,会增加一些额外的CPU开销:
- 收到网卡中断的CPU会向其他CPU发IPI中断,这体现在CPU的%irq上
- 需要处理packet的cpu会收到NET_RX_SOFTIRQ软中断,这体现再CPU的%soft上。请注意,RPS并不会减少第一个CPU的软中断次数,但是会额外给其他的CPU增加软中断。他减少的是第一个CPU的软中断的执行时间,即,软中断里不再需要那么多的时间去走协议栈做包解析,把这个时间给均摊到其他的CPU上去了。
量化对比数据
硬中断次数的变化
这可以通过/proc/interrupts来观察
1
| |
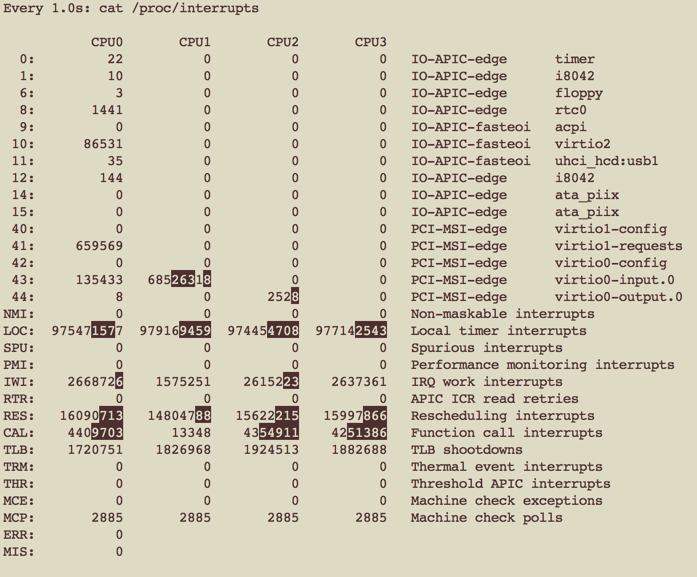
使能RPS之后:
使能RPS之前:
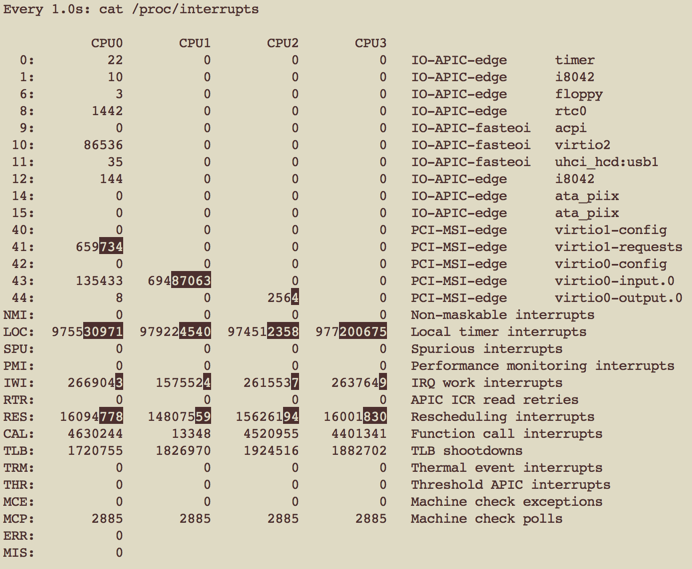
可以看到,是能RPS后,增加了很多的Function call interrups,即IPI。
而virtio0-input.0(虚拟网卡产生的中断,类似于图中NIC产生的中断)仍然只发给CPU1.
也可以通过dstat来看整体次数的对比
- 使能RPS之后:
1 2 3 4 5 6 7 | |
- 使能RPS之前:
1 2 3 4 5 6 7 8 | |
软中断次数的变化
这可以通过/proc/softirq来观察
1
| |
使能RPS之前:
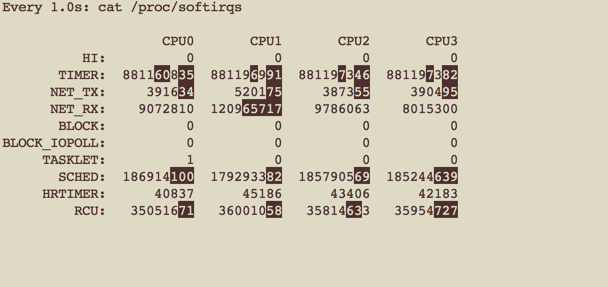
使能RPS之后:
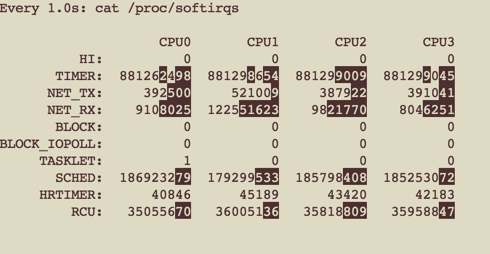
可以看到,CPU1上的RX_NET数相差不大比较接近,但是CPU0/2/3上各自都增加了NET_RX.
各个CPU利用率的变化
这可以通过mpstat来观察
1
| |
- 使能RPS之后
1 2 3 4 5 6 | |
- 使能RPS之前
1 2 3 4 5 6 | |
可以看到,整体而言,CPU的%soft增大了很多,%usr下降了一些。
我们知道%usr是衡量用户态程序性能的一个指标,%usr越高,意味着执行业务代码的时间就越多。如果%usr下降,那就意味着执行业务代码的时间变少了,这显然对于业务性能是一个危险信号。
至于%usr里面如何来提高业务代码执行效率,是另外的问题了,不讨论。
结论,RPS适用的场景
使能了RPS后,会增加CPU的%soft,如果业务场景本身就是CPU密集的,CPU的负载已经很高了,那么RPS就会挤压%usr,即挤压业务代码的执行时间,从而导致业务性能下降。
适用场景
RPS如果想要提升业务性能,前提是除了网卡中断所在的CPU外,其他的CPU都需要有一定的空闲时间,这样使能RPS才能带来收益,否则就会带来额外开销导致性能下降。
在这个场景下,RPS搭配RFS会带来更好的收益,不讨论。
有没有更优的解决方案?
答案肯定是有的。
It is a SECRET!