为什么发送segment fault信号的进程总是PID0 ?
TL;DR
让我们先来看一个小程序。
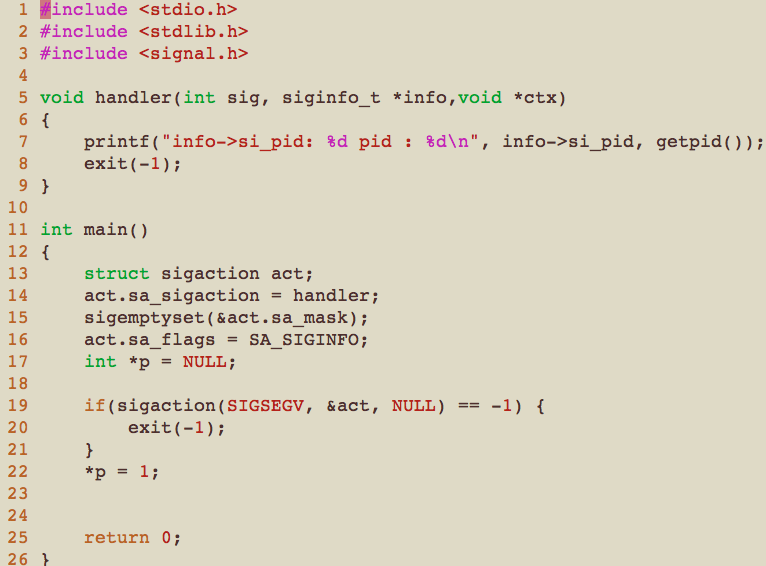
这个小程序的大概意思就是,注册了一个segmentation fault的handler, 在该handler里把SIGSEGV信号的一些信息打印出来,我这里打印了两个值,一个是进程自身的PID,另外一个是info->si_pid, Linux内核里对它的解释是发送信号的进程的PID。
来看下它的执行结果:

我们可以看到当前进程的PID是1060,info->si_pid的值则是0。
我们看下<sys/signal.h>对si_pid的解释,
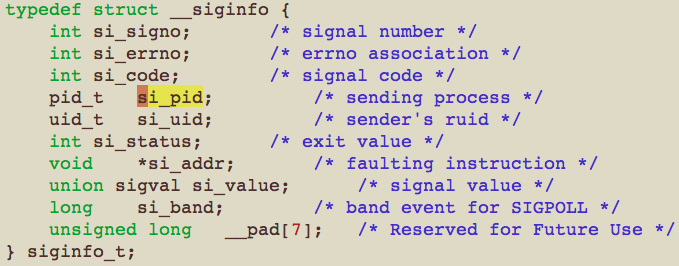
这里清清楚楚的写的是,sending process,即发送该信号的进程ID。
于是,问题就来了,为什么SIGSEGV信号的发送进程是PID0 哪?
Signal机制
我们从头来理一下Kernel对signal的处理机制, 以我们前面这个小程序为例。
在我们的程序里,Line 17定义了一个指针p并初始化为NULL,接着在Line 22对p指向的内容赋值为1,我们都已经知道对空指针解引用会导致segment fault。那么,segment fault具体是怎么产生的?
Kernel为了提高App的执行效率采取的是惰性分配机制,即只有在第一次写的时候才会给它分配具体的物理内存。那么在Line 22由于还没有为指针p分配物理内存,所以这里会首先产生一个缺页异常(page fault), 通过缺页异常陷入内核,接着执行内核的缺页异常处理流程。在内核缺页异常处理流程里,它判断出这是一个用户态的缺页异常,于是就尝试该缺页异常是否可以通过一些手段来解决掉。很遗憾的是,由于没给p申请内存空间,所以p不属于合法的vma区域,即所谓的bad area。于是就产生一个SIGSEGV信号给我们的这个进程。于是异常流程就执行完毕了,开始返回用户态。在返回用户态之前,进程会判断是否有信号需要处理。由于在之前产生了一个SIGSEGV信号,所以又去执行SIGSEGV的信号处理流程了,注意此时已然是在user land来执行了。SIGSEGV的默认处理流程是产生一个segment fault,并且生成一个core文件。由于我们这个程序自己注册了一个SIGSEGV的信号处理程序void handler (int sig, siginfo_t *info, void *ctx), 从内核态返回后就开始执行这个handler函数。 在信号处理程序结束后,如果没有让程序退出,即没有那个exit(-1), 那么就返回到我们程序产生异常的地方,即Line 22,继续执行(PS : 这就是为什么如果没有这个exit,该程序就会死循环的原因)。 这就是Line 22这个语言在内核里的一些动作。
从我们的这个分析可以看出,应该不关PID0鸟事才会。可是事实现实,PID0确实插了一脚,很困惑不是,它到底插在哪儿了哪?
唯一的可能之处就是SIGSEGV产生的地方。我们打开Kernel代码来看看这里到底发生了什么。

这一小段代码就是SIGSEGV产生的地方。可以看到这里对info的si_signo/si_error/si_addr进行了赋值,在前面还对si_code进行了赋值,即SIGSEGV信号只用到了这四个字段。 也就是说,对于SIGSEGV而言,si_pid啥意义都没有。
我们可以对比看下SIGKILL这个信号。
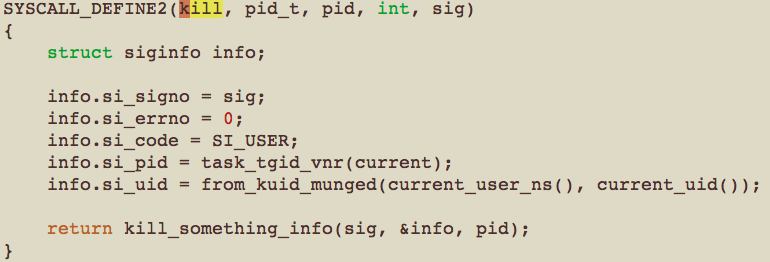
可以看到在产生SIGKILL的地方,将当前的活动进程赋值给了si_pid, 这也是我们在终端里按下CRTL+C来杀死一个进程的原理。接受键盘输入的进程(bash进程)给目标进程发送了一个SIGKILL信号,然后就把目标进程干掉了。
结论
想了并研究了这么一段时间,却得出了这么一个结论(对SIGSEGV而言,si_pid没有任何意义也就没处理),表示很失望,Kernel工程师能够再爱岗敬业一些么? 至少把那句注释“sending process”改称“sending process(if needed)” 也好么,至少不会引起太多的误解。