性能优化,关于Profiling
先贤的教诲
对于大型软件系统而言,可维护性是很重要的一个方面,否则到了最后没人能够搞懂全部的代码那就是一个灾难了。这方面的例子可谓比比皆是,比如华为VRP平台的Linux内核,因为模块间耦合太严重很难升级Linux内核版本,搞到最后实在搞不下去,于是团队解散,投奔中软的RTOS。松本行弘在《代码的未来》这本书里说,开发人员的成本越来越高,机器成本则是越来越便宜,所以我们的编程语言应该要侧重于开发效率和维护效率,而不应该太过于关注性能,至于性能这件事,完全可以通过升级更牛逼的硬件来很轻松的搞定。其实Ruby之父的这个观点在很久之前就被Donald Kunth说过了,“premature optimization is the root of all evil”。两位大师的观点可谓殊途同归。
Donald Knuth在大多数软件工程师眼里可谓神一般的存在,它的这句名言也一直被码农们牢记在心。 Donald Knuth前辈并不是反对optimization,它只是反对premature optimization,即盲目无意义的优化,optimization应该要针对critical的东西。如何寻找critical的代码,就是一个profiling系统需要做的事情。当然profiling本身也属于可维护性的一部分。
CPU体系结构
Profiling的本质,是为了充分发挥CPU的能力。现代CPU的体系结构已经很牛逼了,但是相对而言,软件开发语言则没多大进步,再加上软件开发人员水平的良莠不齐,直接的后果就是,CPU的能力没有得到充分利用。虽然说使用更牛逼的CPU更牛逼的内存更牛逼的散热系统可以大幅的提高性能,但是在相同的配置下,比别人有更牛逼的表现不是更好嘛。iPhone和三星Andriod手机的对比不就是很好的证明嘛。
现代CPU的流水线体系结构大概是这个样的。
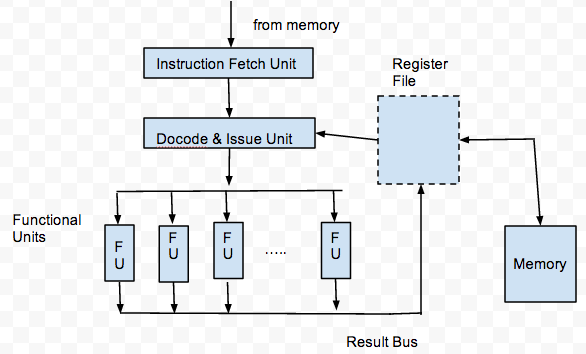
Instruction Fetch Unit用来从memory中取指令到寄存器中,Decode and Issue Unit则是将指令翻译成CPU能够识别的编码然后发射到Functional Units(比如运算器等等)来执行这些指令,FU的执行结果再放回到寄存器中。 所以一条指令的执行完毕最好的情况下需要4个CPU cycles就可以搞定了。我们都已经知道流水线的原理就是,指令A在FU执行时,指令B在译码准备发射,指令C在被从内存中读取到寄存器中,于是这样就实现了不同指令的并行工作来提高CPU的效率。 CPU的这个设计思想被Unix开发人员学来了,于是就是有了管道(pipe)。再接着Erlang又把管道的原理用在了语言特性上来实现并发编程,最后Golang又把Erlang的管道特性给学了去。这并不是说CPU的设计人员有多么牛逼,而是说,软件开发人员要在CPU设计人员制定的规则下做事才能充分利用CPU的性能。
编译器分支预测
CPU的这种流水线存在的缺点,或者说,要依赖编程人员水平的地方在于,指令A可能是JUMP D,这样就导致指令B和指令C要被从流水线里面刷出去了,就造成CPU cycle的浪费。 要想避免这种浪费,就要要求程序自身具有很好的分支预测特性,即要充分迎合CPU的这种预测执行的特性。 在Linux内核里面随处可见的likely()/unlikely()就是做这个事情的,likely()/unlikely()是告诉编译器把if/while的代码块是紧挨着前面的代码还是放置到整个函数的最后面(因为if/while的汇编实现本来就是一个jump指令,所以可以把它跳转到任意合适的位置,这优点类似于goto)。因为CPU最后执行的是编译器生成的二进制,而不是我们写的代码,所以一个好的编译器对于程序性能的影响是巨大的。现在的编译器要比程序员聪明的多,它往往能够预测出程序接下来要执行的指令是什么,有时候我们加的likely()/unlikely()可能根本就没有意义甚至适得其反,因为程序员相比编译器而言太蠢了。有一个例子就是real-time Linux Kernel的maintainer Steven Rostedt做的一个统计,他发现内核里面有大量误用likely()/unlikely()的地方,其中在page_mapping()函数里面的一个unlikely()有39%的概率是错误的,然后这位大神就提交了一个patch把这个unlikely()给去掉了。所以,如果你没有十足的把握,就不要随便使用unlikely()/likely()这俩宏。 不过有一个基本准确的经验就是,在错误处理的分支上加unlikely()大致不会是坏事。比如:
1 2 3 4 | |
这里的unlikely()在绝大多数情况下都不是有害的,不过,如果这段代码是non-critical的,那么这个unlikely()就是non-sense的,因为在这种情况下它对性能的提升可能近似为0.0000%。即使这段代码真的是critical的话,这个unlikely()并非就有必要去添加,因为编译器在编译的时候自己也能够判断出来。
曾有人对linux kernel里面likely/unlikely的使用情况做过统计,发现unlikely()的使用次数大概是likely()的10倍,就是很多错误处理的分支都加了unlikely()的缘故。
对于likely/unlikely的使用的一个基本原则是,只有在critical path里面,我们才去考虑使用它,是否有必要去使用likely/unlikely还需要借助它的反汇编代码来进一步验证。比如,如下两段反汇编是添加了likely和没有添加likely的的对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
假设cacheline的大小是128bytes,我们可以看到在第二种情况时,if语句会跳转到另外一个cache line里面,这必然会造成cache miss,如果t1在大多数情况下都是0x7fffffff,那么这里就会有较明显的性能损失。
除了这个分支预测之外,还有一个性质对流水线的影响较大,那就是数据依赖。指令B已经译码完成,准备要发出去的时候,发现它的操作数不可用,有可能别的CPU在使用这个操作数,于是指令B只能在这里傻傻的等待另外的CPU释放这个操作数。
所以对于流水线型的CPU,主要就这两方面决定着性能的好坏:1)数据依赖 2)分支预测。现在的并发编程也主要是解决的这两件事。
CPU的设计人员为了让程序员能够更直观的感受这两件事的表现,就给程序员提供了一些性能统计的寄存器,这些寄存器都在协处理0里面。他们做的事情,就是统计多长时间cpu cycle内,指令的issue/retire的数目,icache/dcache的hit/miss,以及l2 icache/dcache的hit/miss等等。比如说,如果icache的miss较大,那显然是程序的分支预测较差。
对于应用程序开发人员而言,是没有必要了解这么详细的性能寄存器信息的,或者说在这个上面花费精力意义不大。因而就有了perf、oprofile、systemtap、dtrace这些性能调试工具的应运而生。这些工具提供给程序员更友好的方式来分析程序,借助这些工具能够很直观的找到程序的critical部分。
P.S.
[1] 图是用Google Doc画的,第一次使用Google Doc画图,画的不太好:(